



Agents Today #13 - Building Your Own Deep Research AI Agent: Options, Methods, and Best Practices
We turn to perhaps the most ambitious question: How can you build your own Deep Research AI agent?


In our previous substack posts, we explored the emergence of Deep Research agents (#9 Introduction), compared their performance (#10 Performance Comparisons), examined their tendency to confidently answer impossible questions (#11 The Factuality Problem), and discussed how to craft effective prompts (#12 Crafting the Perfect Prompt). Now we turn to perhaps the most ambitious question: How can you build your own Deep Research AI agent?
We will be departing from Deep Research for the next few posts. I would love feedback on what has been helpful and things you would like to see more of.
Summary
While commercial Deep Research offerings from OpenAI, Google, Perplexity, and Grok provide powerful capabilities, building your own agent offers significant advantages for specialized needs. This article explores the motivations for creating custom Deep Research agents—from data privacy and specialized domain knowledge to avoiding usage limitations and implementing custom reasoning methods. We examine four approaches: integrating proprietary data with existing platforms, using no-code orchestration tools, leveraging AI agent frameworks, and adapting open-source research projects. Each approach presents distinct trade-offs in terms of development complexity, customization potential, and resource requirements. For organizations with sensitive data or specialized research needs, custom Deep Research agents can provide capabilities that commercial offerings cannot match, though they require careful design and evaluation to ensure reliable and consistent performance.
Mike's Insights
After exploring commercial Deep Research offerings and their capabilities, I've found that some organizations and individuals have compelling reasons to build their own solutions. The commercial options are impressive and continuously improving, but they fundamentally operate as black boxes with predetermined workflows, data access and limitations.
Building your own Deep Research agent isn't about reinventing the wheel—it's about creating a research tool for your specific needs, data sources, and methodologies. The approaches I outline range from relatively simple integrations to more complex custom implementations
Remember that even with a custom-built agent, the quality of your results will still depend heavily on how you structure your prompts and queries. The prompt engineering principles we discussed in the previous article remain essential, regardless of whether you're using a commercial service or your own custom solution. Additionally, if you're working with proprietary data, I strongly recommend building your own benchmark based on prior research to evaluate system quality and understand the impact of different models and prompts.
One thing I do not dig into here but is worth noting. Deep research on public data depend heavily on the quality of the initial search query. While Google has the advantage of it's own search infrastructure and assuming OpenAI leverages it's Microsoft relationship for Bing, it is less clear how the other commercial offerings do their initial search. There are some API offerings available but make sure you test them before you depend on them.
Why Would You Build Your Own Deep Research Agent?
It's worth examining the motivations for building a custom Deep Research agent rather than using commercial offerings.
Domain Specialization and Customization
Commercial Deep Research agents are designed for general-purpose research across the public web. However, many organizations operate in specialized domains with unique terminology, concepts, and information sources. Building your own agent allows you to give it access to highly specialized data relevant to your particular needs, making it more effective at domain-specific research tasks.
For example, a pharmaceutical company might build a Deep Research agent specifically trained on medical literature, clinical trial data, and proprietary research documents.
Data Privacy and Security
Perhaps the most compelling reason to build a custom Deep Research agent is data privacy. Commercial services require sending your queries—and potentially sensitive information—to external servers. With proprietary research agents, you maintain complete control over your data without sharing sensitive information with third-party services.
This is particularly important for organizations working with confidential information, such as legal firms handling privileged client information, financial institutions analyzing market data, or government agencies working with classified material. A self-hosted Deep Research agent can operate entirely within your secure environment, ensuring that sensitive information never leaves your control.
Integration with Proprietary Systems
Custom agents can be designed to seamlessly connect with your organization's existing tools, databases, and workflows. This integration capability allows the agent to access internal knowledge bases, document management systems, and specialized databases that commercial offerings cannot reach.
For instance, a research institution might build an agent that can query both public academic databases and their internal research repositories, providing comprehensive coverage that no commercial solution could match. Similarly, a legal firm might create an agent that integrates with their case management system and document database, allowing for research that spans both public legal resources and the firm's own precedents and work product.
Control Over Reasoning Methods
Different research domains require different reasoning approaches. Building your own agent allows you to implement specific reasoning approaches and research methodologies aligned with your objectives. You can design the agent to follow particular analytical frameworks, apply domain-specific heuristics, or implement specialized evaluation criteria.
For example, a financial analysis firm might implement a research agent that follows specific frameworks for evaluating investment opportunities.
Transparency and Explainability
Commercial Deep Research agents often provide limited insight into how they reached their conclusions. By building your own agent, you can design it to provide clear explanations of its research process, sources, and confidence levels in ways that commercial solutions may not offer.
This transparency is particularly valuable in domains where the reasoning process is as important as the conclusion itself, such as legal research, scientific investigation, or policy analysis. A custom agent can be designed to document each step of its research process, allowing users to trace conclusions back to their sources and understand the logic behind the agent's analysis.
No Usage Limitations
Commercial Deep Research services typically impose usage limits—ChatGPT's Deep Research is limited to 10 queries per month for Plus users and 120 for Pro subscribers, while Perplexity caps free users at 5 queries per day. Building your own agent allows you to avoid these restrictions, enabling unlimited research queries constrained only by your own infrastructure.
This freedom from usage limitations is particularly valuable for organizations that need to conduct extensive research on a regular basis, such as market research firms, academic institutions, or intelligence agencies. With a custom agent, the scale of research is limited only by your computational resources, not by subscription tiers or query allowances.
Customized Citation Standards
Different fields have different standards for citation and source evaluation. Academic research, legal analysis, and journalistic investigation each follow distinct conventions for citing sources and evaluating their credibility. Custom agents can implement specific academic or industry citation standards and source evaluation criteria relevant to your field.
For instance, a legal research agent might be designed to prioritize primary sources like statutes and case law over secondary sources, while an academic research agent might implement formal citation styles like APA, MLA, or Chicago.
Reduced Hallucination Risk
As we saw in our article on the factuality problem, commercial Deep Research agents can sometimes generate plausible-sounding but fabricated information. Custom agents can be optimized to minimize hallucinations by implementing stricter fact-checking protocols specific to your domain.
For example, a financial research agent might be designed to verify all numerical claims against multiple sources before including them in reports, while a medical research agent might be programmed to clearly distinguish between established medical consensus and emerging hypotheses. These domain-specific safeguards can significantly reduce the risk of misinformation in deep research outputs.
Specialized Retrieval Techniques
Different research domains benefit from different information retrieval approaches. Building your own agent allows you to implement custom retrieval augmentation approaches optimized for your specific knowledge sources and research needs.
Competitive Advantage
In many industries, research capabilities directly translate to competitive advantage. Proprietary research agents can provide unique insights and capabilities that aren't available to competitors using standard commercial tools. This advantage can be particularly significant in knowledge-intensive fields like consulting, financial analysis, or competitive intelligence.
By building a research agent specifically tailored to your organization's needs and knowledge base, you can develop research capabilities that differentiate your services and provide insights that competitors cannot easily replicate.
Best Practices for Custom Deep Research Agents

Regardless of which implementation approach you choose, several best practices can help ensure the success of your custom Deep Research agent:
1. Start with Clear Research Objectives
Before building your agent, clearly define what types of research it needs to perform and what outputs it should generate. Understanding your specific research needs will guide decisions about tools, data sources, and implementation approach.
For example, a market research agent might need to focus on gathering competitive intelligence and industry trends, while a scientific research agent might prioritize academic literature and experimental data. These different objectives lead to different design choices.
2. Implement Robust Source Evaluation
One of the key challenges in Deep Research is distinguishing reliable information from low-quality or biased sources. Implement explicit source evaluation criteria in your agent, considering factors like:
Author credentials and expertise
Publication reputation and peer review status
Recency and relevance
Methodology and evidence quality
Potential conflicts of interest
These criteria should be tailored to your specific domain—what constitutes a reliable source differs between your requirements.
3. Design for Transparency and Explainability
Ensure your agent provides clear explanations of its research process and reasoning. Users should be able to understand how the agent arrived at its conclusions and what sources informed its analysis. This transparency builds trust and allows for critical evaluation of the research outputs.
Practical implementations include:
Detailed citation of sources with direct quotes where appropriate
Log explicit reasoning steps showing how conclusions were derived
Confidence ratings for different assertions
Clear distinction between factual information and inference
4. Build in Factuality Safeguards
As we saw in our article on the factuality problem, even sophisticated AI systems can generate plausible-sounding but fabricated information. Implement safeguards to minimize this risk:
Require multiple source verification for key claims
Implement cross-checking between different information sources
Design prompts that emphasize accuracy over comprehensiveness
Include explicit instructions to acknowledge uncertainty rather than confabulate
Build a QA process for your report using other models and tools.
5. Create Evaluation Benchmarks
Develop benchmarks to evaluate your agent's performance based on research tasks relevant to your domain. These benchmarks should include:
A diverse set of research questions typical of your use cases
Ground truth; known good answers or expert generated responses for comparison
Metrics for evaluating accuracy, comprehensiveness, and relevance
Tests specifically designed to detect hallucination or fabrication, having a control.
Build the benchmark to be well beyond your current capabilities. It should not focus on where your business is but ultimately where you want it to be in the future.
Regular evaluation against these benchmarks helps identify areas for improvement and ensures the agent continues to meet your research needs.
6. Implement Human in the Loop Processes
For critical research tasks, design your agent to collaborate with human expert(s) rather than operating completely autonomously. This hybrid approach combines the efficiency of AI with human judgment and expertise.
Effective human in the loop implementations include:
Review points where humans validate intermediate findings
Options to guide the research direction based on initial results
Mechanisms for humans to provide additional context or correct misunderstandings
Final review processes before research outputs are used for decision-making
7. Plan for Continuous Improvement
Research and tool need to evolve, and AI capabilities advance rapidly. Design your agent to be modular and extensible.
Monitor performance metrics to identify areas for enhancement
Collect and track user feedback on research outputs and process
Regularly update source evaluation criteria and research methodologies
Schedule regular improvements to the benchmark.
Implementation Approaches

If you've decided to build your own Deep Research agent, several implementation approaches are available, ranging from relatively simple integrations to more complex custom solutions. Each approach offers different trade-offs in terms of development complexity, customization, and resource requirements. The following table provides an overview to help you select the most appropriate approach for your needs:
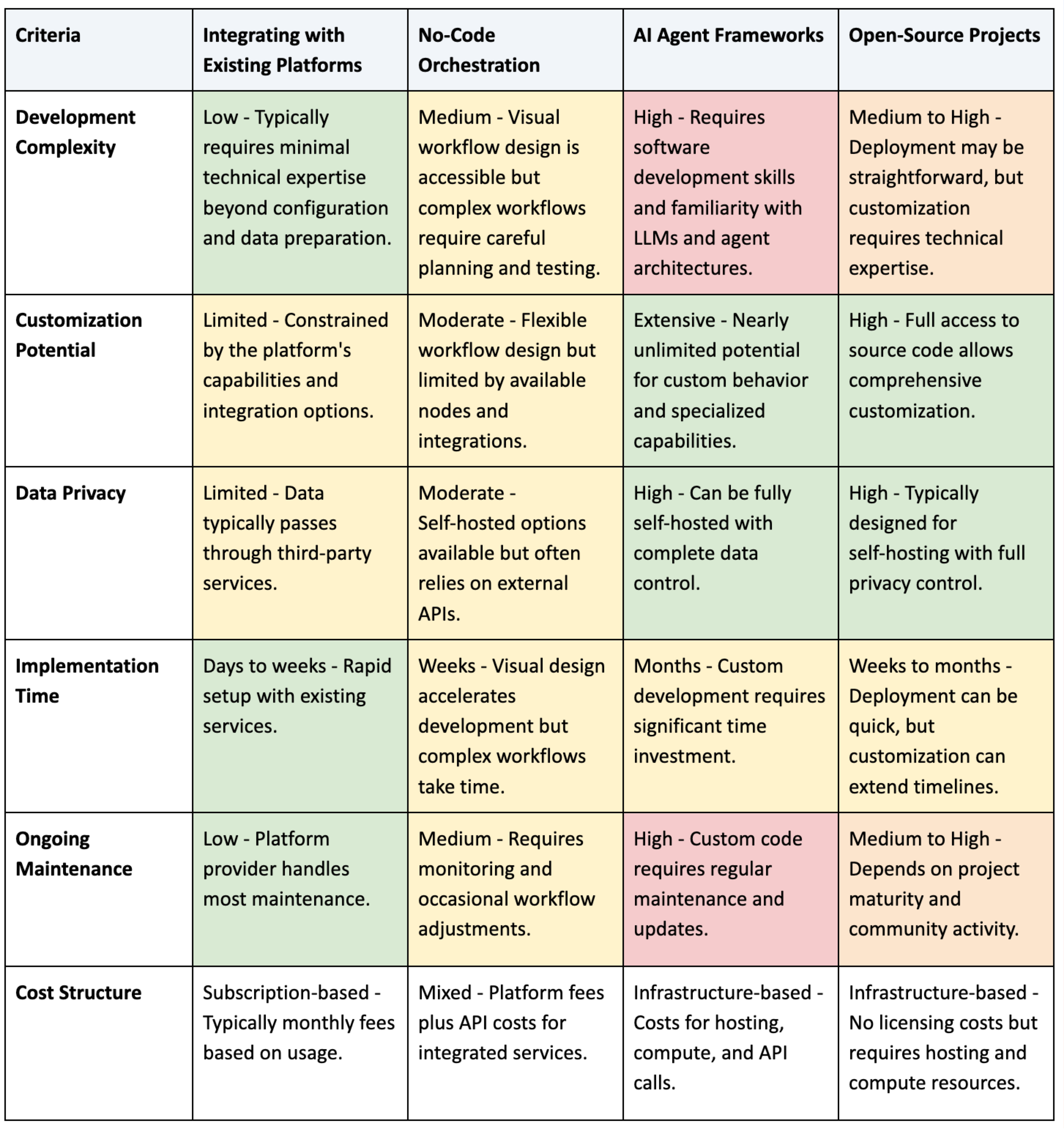
Approach 1: Integrating Proprietary Data with Existing Platforms
The simplest approach to building a custom Deep Research agent is to integrate your proprietary data with existing platforms that support custom knowledge bases. This approach leverages the capabilities of established services while adding your own specialized information.
Implementation Options:
You.com: You.com offers the ability to create custom GPTs that can access both the public web and your proprietary data sources. Their platform allows you to upload documents, connect to databases, or integrate with internal knowledge bases, creating a research agent that combines public and private information.
Perplexity for Teams: Perplexity's enterprise offering allows organizations to connect their internal data sources to the Perplexity research engine. This creates a custom research experience that can search across both public information and private repositories.
Kagi Universal Summarizer: While not a full Deep Research agent, Kagi's Universal Summarizer can be integrated with custom data sources to provide research capabilities across proprietary information.
Benefits:
This approach offers several advantages:
Relatively low development complexity
Leverages the sophisticated capabilities of established platforms
Minimal infrastructure requirements
Faster implementation timeline
Limitations:
However, this approach also has significant limitations:
Less control over the research methodology and reasoning process
Potential data privacy concerns, as your information still passes through third-party services
Limited customization of the agent's behavior and capabilities
Best For:
This approach is ideal for organizations that:
Need a quick implementation with minimal development effort
Have minimal customization requirements
Are comfortable with some data sharing with trusted third parties
Want to leverage sophisticated existing capabilities without building from scratch
Approach 2: No-Code Orchestration Tools
For those seeking more control without extensive coding, no-code orchestration platforms like n8n and Make.com offer powerful tools for building custom research workflows. These also allow for more triggers and use of the data beyond the initial research.
n8n: Open-source workflow automation tool for creating sophisticated research workflows
Make.com (formerly Integromat): Visual interface for creating automated workflows
These platforms allow you to visually design complex research processes that integrate multiple services and data sources.
Implementation Options:
n8n: This open-source workflow automation tool allows you to create sophisticated research workflows by connecting various services and APIs. n8n offers templates specifically designed for Deep Research, including workflows that combine web search, content extraction, and LLM-powered analysis.
A typical n8n Deep Research workflow might include:
A trigger node that initiates the research process based on a user query or some other event
Search nodes that query multiple sources (Google, Bing, academic databases)
HTTP request nodes that retrieve and extract content from search results
LLM nodes (connecting to OpenAI, Anthropic, or other providers) that analyze and synthesize the retrieved information
Document generation nodes that format the results into comprehensive reports
Make.com (formerly Integromat): Similar to n8n, Make.com provides a visual interface for creating automated workflows. It offers extensive integration options with various search APIs, content extraction tools, and AI services, allowing you to build custom research processes without coding.
Benefits:
The no-code approach offers significant advantages:
Visual design makes complex workflows accessible to non-developers
Highly flexible integration with diverse services and data sources
Greater control over the research process compared to third-party platforms
Ability to implement custom logic and decision points in the research workflow
Limitations:
However, this approach also has limitations:
May require subscription costs for the orchestration platform
Performance can be affected by the platform's execution limits
Complex workflows can become difficult to configure, manage and debug
Still depends on external APIs for core functionality like search and content analysis
Best For:
This approach is well-suited for:
Rapid prototyping
Teams with limited development resources but technical aptitude
Organizations that need moderate customization of the research process
Use cases requiring integration of multiple specialized data sources
Approach 3: AI Agent Frameworks
For more sophisticated custom agents, several AI agent frameworks provide the building blocks for creating powerful Deep Research capabilities. These frameworks offer greater flexibility and control than no-code tools, though they require more technical expertise to implement.
LangChain: Popular framework providing components for building LLM-powered applications
CrewAI: Framework for orchestrating multiple specialized agents working together
LlamaIndex: Framework specializing in connecting LLMs with external data sources
Implementation Options:
LangChain: This popular framework provides components for building LLM-powered applications, including agents that can perform research tasks. LangChain offers tools for document loading, text splitting, embedding generation, vector storage, and retrieval, making it well-suited for building research agents that can access and analyze diverse information sources.
A LangChain-based research agent typically includes:
Document loaders for ingesting content from various sources
Text splitters for breaking documents into manageable chunks
Embedding models for converting text into vector representations
Vector stores for efficient similarity search
Retrieval components for finding relevant information
Agent executors that orchestrate the research process using LLMs
CrewAI: This framework focuses on orchestrating multiple specialized agents that work together as a "crew" to accomplish complex tasks. For Deep Research, CrewAI allows you to create teams of agents with different roles—such as searchers, analyzers, critics, and writers—that collaborate to produce comprehensive research outputs.
A CrewAI research implementation might include:
A research planner agent that breaks down the query into sub-questions
Multiple search agents that gather information from different sources
Analysis agents that evaluate and synthesize the gathered information
A critic agent that identifies gaps or inconsistencies
A writer agent that produces the final research report
LlamaIndex: This framework specializes in connecting LLMs with external data sources, making it particularly well-suited for research agents that need to access proprietary information. LlamaIndex provides tools for data ingestion, indexing, and retrieval, allowing you to build agents that can efficiently search and analyze large document collections.
Benefits:
AI agent frameworks offer substantial advantages:
Extensive flexibility and customization potential
Direct control over the entire research process
Ability to implement sophisticated reasoning and analysis capabilities
Support for diverse data sources and retrieval methods
Potential for self-hosting to ensure data privacy and security
Limitations:
However, this approach also presents challenges:
Requires significant development expertise
More complex to implement and maintain
May involve substantial infrastructure requirements
Requires careful design to ensure reliable performance
Best For:
This approach is ideal for:
Use cases requiring sophisticated custom reasoning
Scenarios where maximum control over the research process is essential
Applications involving highly sensitive or specialized information
Approach 4: Open-Source Deep Research Projects
Several open-source projects specifically focus on building Deep Research capabilities, offering ready-made solutions that can be adapted to your needs. These projects provide a head start on implementing custom research agents without building everything from scratch.
GPT Researcher: Open-source autonomous agent designed for comprehensive online research
Open Deep Research: Project creating similar open-source capabilities to OpenAI's Deep Research capability
AutoGen: Microsoft's framework for creating conversational AI agents that collaborate
Implementation Options:
GPT Researcher: This open-source autonomous agent is specifically designed for comprehensive online research. It uses LLMs to iteratively search the web, scrape content, and compile detailed reports with citations. GPT Researcher can be self-hosted and customized to meet specific research requirements.
Open Deep Research: This project aims to create an open-source equivalent of OpenAI's Deep Research capability. It leverages Firecrawl for extraction and search, combined with a configurable reasoning model to perform in-depth web research. The project is built using modern web development technologies and can be self-hosted.
AutoGen: Developed by Microsoft, this framework enables the creation of conversational AI agents that can collaborate to solve complex tasks. AutoGen provides a foundation for building research agents that can engage in sophisticated multi-step reasoning and information gathering.
Benefits:
Open-source projects offer unique advantages:
Community support and ongoing development
Complete transparency into the implementation
No licensing costs (though infrastructure costs still apply)
Full customization potential
Limitations:
However, this approach also has drawbacks:
May require significant adaptation for specialized needs
Documentation and support can be less comprehensive than commercial options
Stability and reliability may vary depending on the project's maturity
Requires technical expertise to deploy and customize
Best For:
This approach is well-suited for:
Organizations with technical resources but limited budget
Use cases that align well with the project's existing capabilities
Scenarios where transparency and customization are paramount
Applications where community support and open development are valued
Conclusion

Building your own Deep Research AI agent could represent a significant investment of time and resources, but for organizations with specialized research needs, the benefits can far outweigh the costs. Custom agents offer control over the research process, integration with proprietary data sources, and tailored capabilities that commercial offerings cannot.
The implementation approach you choose—whether integrating with existing platforms, using no-code orchestration tools, leveraging AI agent frameworks, or adapting open-source projects—should align with your technical capabilities, research requirements, and resource constraints. Each approach offers different trade-offs in terms of development complexity, customization potential, and ongoing maintenance.
Regardless of your chosen approach, success depends on thoughtful design, robust evaluation, and continuous improvement. As AI technology continues to advance, the capabilities of custom Deep Research agents will only grow more sophisticated. Organizations that invest in building these tools today may be well-positioned to leverage these advancements, gaining a significant competitive advantage for knowledge-intensive domains.
** One of the options I did not discuss was building a Deep Research Agent form scratch. I thought I would at least outline an example of doing that. The following section is entirely AI generated with limited testing. If you want to try this approach and have not written any code before, you could take the requirements outlined above and use an AI Coding Agent, like Replit.com, to build a function prototype.

"Vibe Authoring": Building a Basic Deep Research Agent: A Practical Example
To illustrate the process of building a custom Deep Research agent, let's walk through a simplified example using LangChain, one of the most popular AI agent frameworks. This example demonstrates the core components of a research agent without delving into every implementation detail.
FAISS: Facebook AI Similarity Search for efficient vector search
Tavily: Search API for AI applications referenced in the code example
Wikipedia API: Python library for accessing Wikipedia content
Step 1: Setting Up the Environment
First, we need to install the necessary packages and set up our environment:
pip install langchain langchain_openai langchain_community faiss-cpuWe'll also need API keys for the services we'll be using:
import os
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["TAVILY_API_KEY"] = "your-tavily-api-key" # For web searchStep 2: Creating the Research Agent
Now we can create a basic research agent using LangChain's agent framework:
from langchain_openai import ChatOpenAI
from langchain.agents import create_openai_functions_agent
from langchain.agents import AgentExecutor
from langchain.prompts import ChatPromptTemplate
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities.wikipedia import WikipediaAPIWrapper
# Define our tools
search_tool = TavilySearchResults(max_results=5)
wikipedia = WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
tools = [search_tool, wikipedia]
# Create a prompt template that emphasizes thorough research
prompt = ChatPromptTemplate.from_template("""
You are a Deep Research AI agent designed to conduct comprehensive research on complex topics.
Your goal is to provide detailed, accurate, and well-sourced information.
When researching, follow these principles:
1. Break down complex questions into manageable sub-questions
2. Search for information from multiple sources
3. Verify facts across different sources when possible
4. Clearly cite your sources
5. Acknowledge uncertainty when information is limited or contradictory
Research Question: {input}
Take your time to explore this topic thoroughly before providing your final answer.
""")
# Create the agent
llm = ChatOpenAI(model="gpt-4o", temperature=0)
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)Step 3: Running the Research Process
With our agent set up, we can now execute a research query:
research_question = "What are the environmental impacts of lithium mining for electric vehicle batteries, and what alternatives are being developed?"
result = agent_executor.invoke({"input": research_question})
print(result["output"])This basic example demonstrates the core components of a Deep Research agent:
Tools for information gathering (Tavily search and Wikipedia in this case)
A prompt that guides the research approach
An LLM for reasoning and synthesis
An agent executor that orchestrates the process
A production-ready Deep Research agent would include additional components:
More sophisticated search and content extraction capabilities
Document processing for handling PDFs, academic papers, etc.
Memory systems for maintaining context across multiple research steps
Evaluation mechanisms to assess source quality and information reliability
Structured output formatting for consistent reporting
Step 4: Enhancing with Retrieval Augmentation
To incorporate proprietary data, we can add retrieval augmentation:
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import DirectoryLoader
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
# Load documents from a directory
loader = DirectoryLoader("./proprietary_data/", glob="**/*.pdf")
documents = loader.load()
# Split documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
chunks = text_splitter.split_documents(documents)
# Create vector store
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_documents(chunks, embeddings)
# Create retrieval tool
from langchain.tools.retriever import create_retriever_tool
retriever = vector_store.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"proprietary_data_search",
"Searches and retrieves information from proprietary data sources."
)
# Add to tools
tools.append(retriever_tool)
# Recreate agent with updated tools
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)