



Agents Today #10 - Rise of Deep Research: Performance Comparisons (Part 2)
Comprehensive performance comparison of Deep Research platforms across diverse research topics, revealing significant differences in their capabilities, consistency, and output quality.


In the previous article, we explored the emergence of Deep Research agents from OpenAI, Google, Perplexity, and Grok, examining how these AI tools are transforming online research through autonomous, multi-step processes. This second installment provides a comprehensive performance comparison of these platforms across diverse research topics, revealing significant differences in their capabilities, consistency, and output quality.
Mike's Insights
I wanted to take a moment and leave a few thoughts with you before you read through the rest of this article. Deep Research is a powerful tool, even the poorest performing Deep Research product saves hours and days of knowledge work. Things to consider;
If you are depending on this research for making critical decisions, you should not depend on just one model. While they came to similar conclusions in their reports, there was divergence in the sources of the data to come to these conclusions. Merging multiple reports together and manually checking the citations should become your common practice.
Evaluation of Deep Research is difficult. Many of the industry benchmarks were not developed with agentic capabilities or deep research projects in mind. If you are going to lean on Deep Research for critical decisions, then you should make your own evaluations. Have multiple humans generate deep research results which are similar to your needs, or use existing reports. Run these same requests through each of the Deep Research products and use all of them to judge and compare against the manual reports.
The nature of the topic you are using Deep Research for will also make a difference on the quality of the output. The more verifiable and quantifiable the nature of the topic, the better the better the result.
Topics in the next few posts;
All of these products are developed to be helpful, sometimes too helpful. What does that mean for you?
How do you build the best Deep Research prompt?
Summary
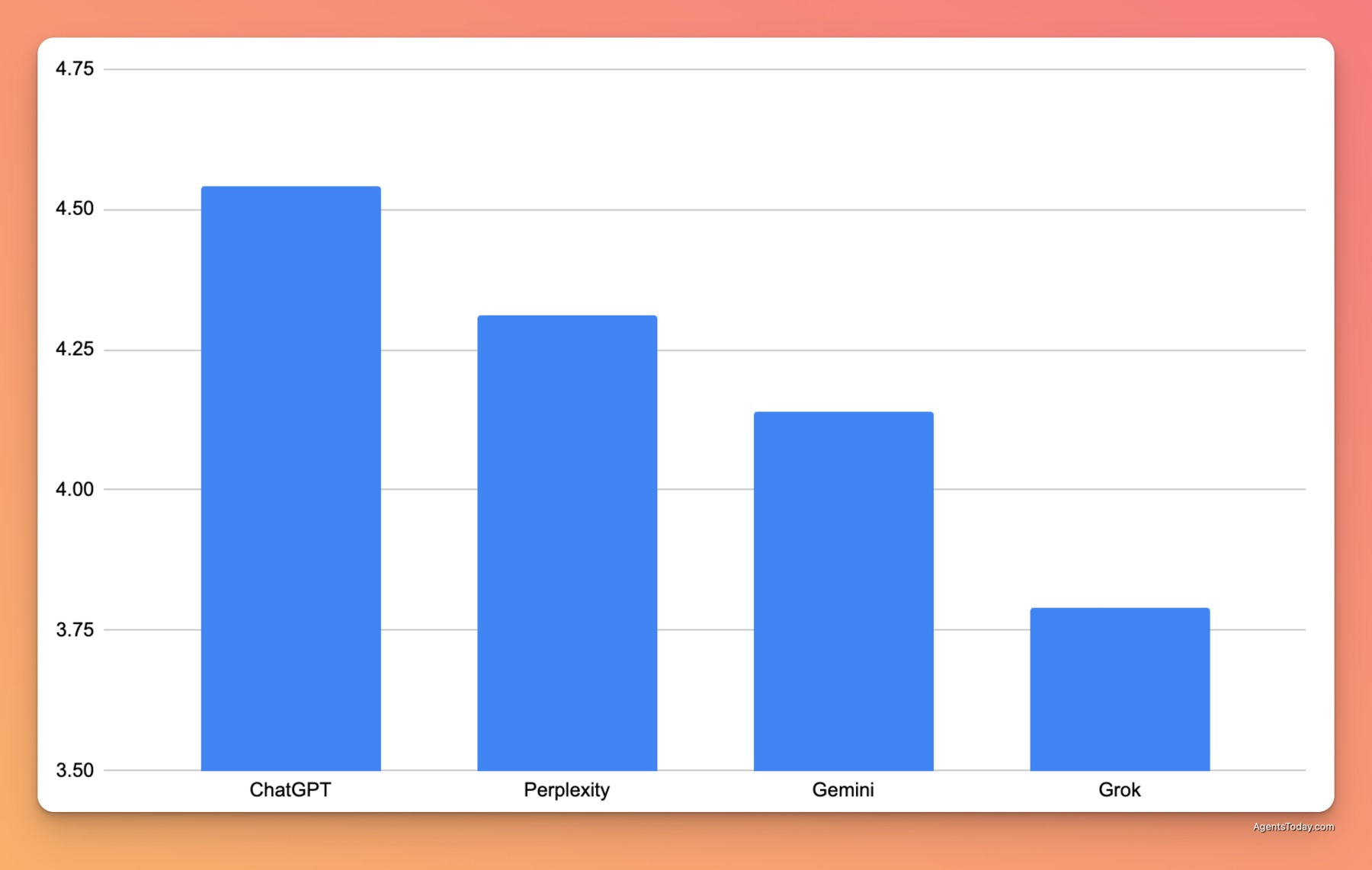
After extensive testing across four complex research topics, ChatGPT emerged as the overall performance leader with the highest average scores (4.54/5), followed by Perplexity (4.31), Gemini (4.14), and Grok (3.79). However, Gemini demonstrated the most consistent performance across all topics, while ChatGPT showed the highest variability. Each platform exhibited distinct strengths: ChatGPT excelled in comprehensiveness and evidence quality, Perplexity performed strongly in political and scientific analysis, Gemini offered reliable consistency, and Grok, despite lower overall scores, led in clarity and readability.
Methodology
To conduct this comparative analysis, I tested each Deep Research agent (ChatGPT, Gemini, Perplexity, and Grok) with identical prompts across four diverse research domains:
Quantum Computing and Encryption: "Provide a comprehensive analysis of how quantum computing could affect current encryption methods, including potential vulnerabilities and mitigation strategies."
Scientific Concept Explanation & Ethical Implications: "Explain the concept of CRISPR gene editing technology. Discuss its potential benefits for treating genetic diseases, but also analyze the ethical concerns surrounding its use, particularly regarding germline editing and equitable access."
Historical & Social Analysis: "Examine the issue of increasing political polarization in democratic societies. Analyze the contributing factors (e.g., social media, economic inequality, media fragmentation) and propose potential solutions from different perspectives (e.g., policy changes, technological interventions, community initiatives)."
AI Ethics in Healthcare: "Discuss the ethical considerations of using AI algorithms to make decisions in healthcare, such as patient triage or treatment recommendations, including potential biases and accountability issues."
For ChatGPT's deeper prompts that required additional clarification, I simply responded with "Make any assumptions you need to answer the prompt" to maintain consistency in the testing process.
Evaluation Framework
To ensure objective assessment, I employed a blind evaluation approach using reasoning models from each provider to judge the outputs. Each response was evaluated using the following criteria:
Comprehensiveness: Coverage of all key aspects of the prompt (1-5 scale)
Logical Coherence: Soundness and structure of the argument or analysis (1-5 scale)
Evidence and Examples: Use of specific examples or data points to support claims (1-5 scale)
Critical Thinking: Ability to analyze different viewpoints or potential counterarguments (1-5 scale)
Clarity and Readability: Quality of writing and ease of understanding (1-5 scale)
This methodology allowed for a systematic comparison across platforms while minimizing potential biases in the evaluation process.
Overall Performance Rankings
Based on average scores across all evaluations, the Deep Research agents ranked as follows:
ChatGPT (Average score: 4.54/5)
Perplexity (Average score: 4.31/5)
Gemini (Average score: 4.14/5)
Grok (Average score: 3.79/5)
ChatGPT demonstrated superior overall performance, leading by a significant margin over the other models. Its responses consistently showed greater depth, better evidence integration, and more nuanced analysis across most topics.
Consistency Analysis
Interestingly, when examining consistency (measured by the coefficient of variation, where lower values indicate more consistent performance), the models ranked differently:
Gemini (CV: 0.024) - Most consistent
Perplexity (CV: 0.053)
Grok (CV: 0.069)
ChatGPT (CV: 0.075) - Least consistent
This reveals that while ChatGPT achieved the highest average scores, Gemini provided the most consistent performance across different topics. Despite ChatGPT's higher quality ceiling, it showed more variability in output quality depending on the research domain.
Performance by Research Topic
Looking at which model performed best for each research topic reveals interesting patterns:
CRISPR Gene Editing Technology
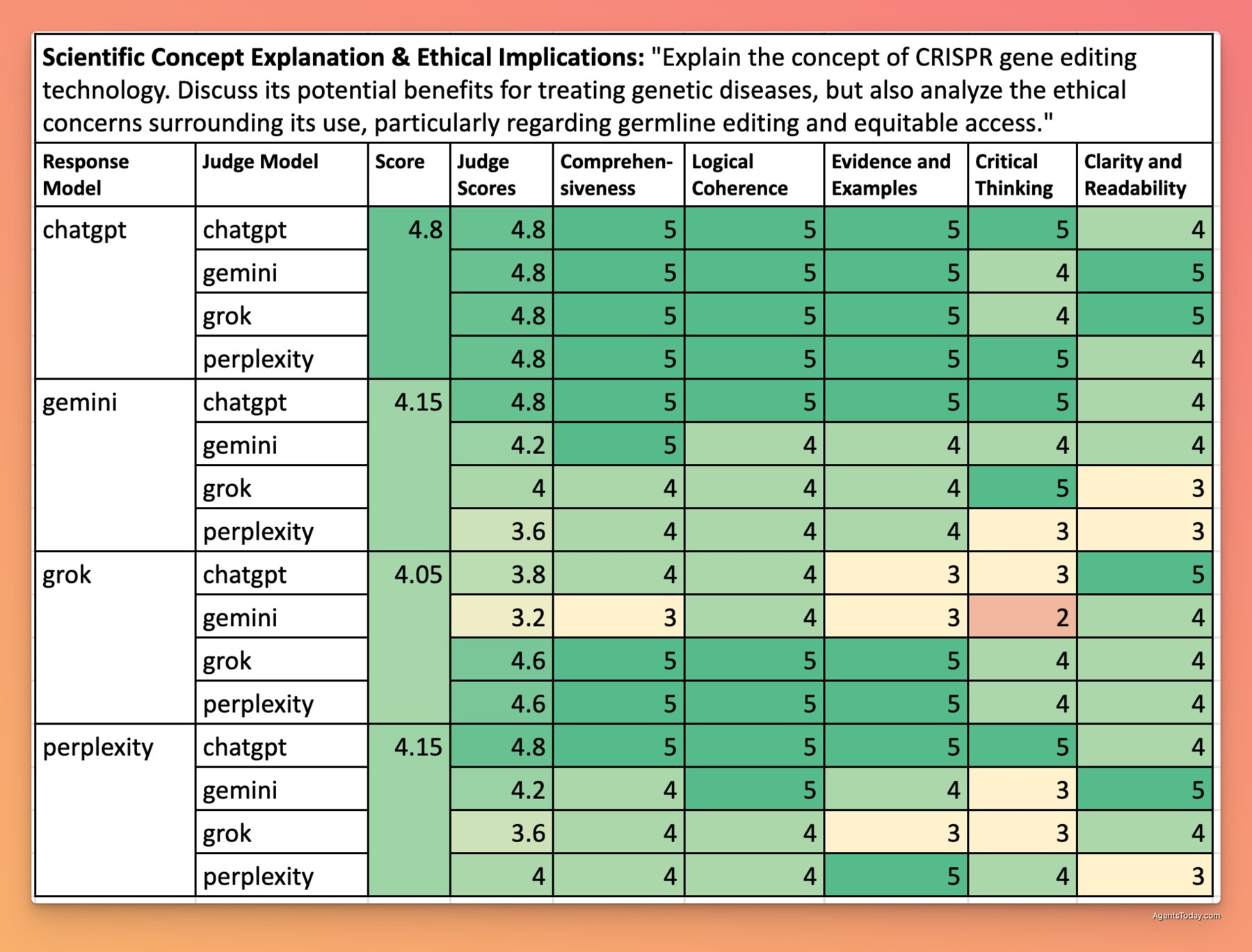
ChatGPT led with a score of 4.80/5, providing exceptional coverage of both the scientific mechanisms and ethical implications. Its response included detailed explanations of the CRISPR-Cas9 system, real-world applications in treating genetic diseases like sickle cell anemia and cystic fibrosis, and a nuanced discussion of ethical concerns around germline editing, designer babies, and global access inequities.
Perplexity (4.40/5) and Gemini (4.25/5) delivered strong performances with comprehensive coverage but less depth in connecting scientific concepts to ethical frameworks. Grok (3.85/5) provided a clear explanation of the basic technology but offered less substantive analysis of the ethical dimensions.
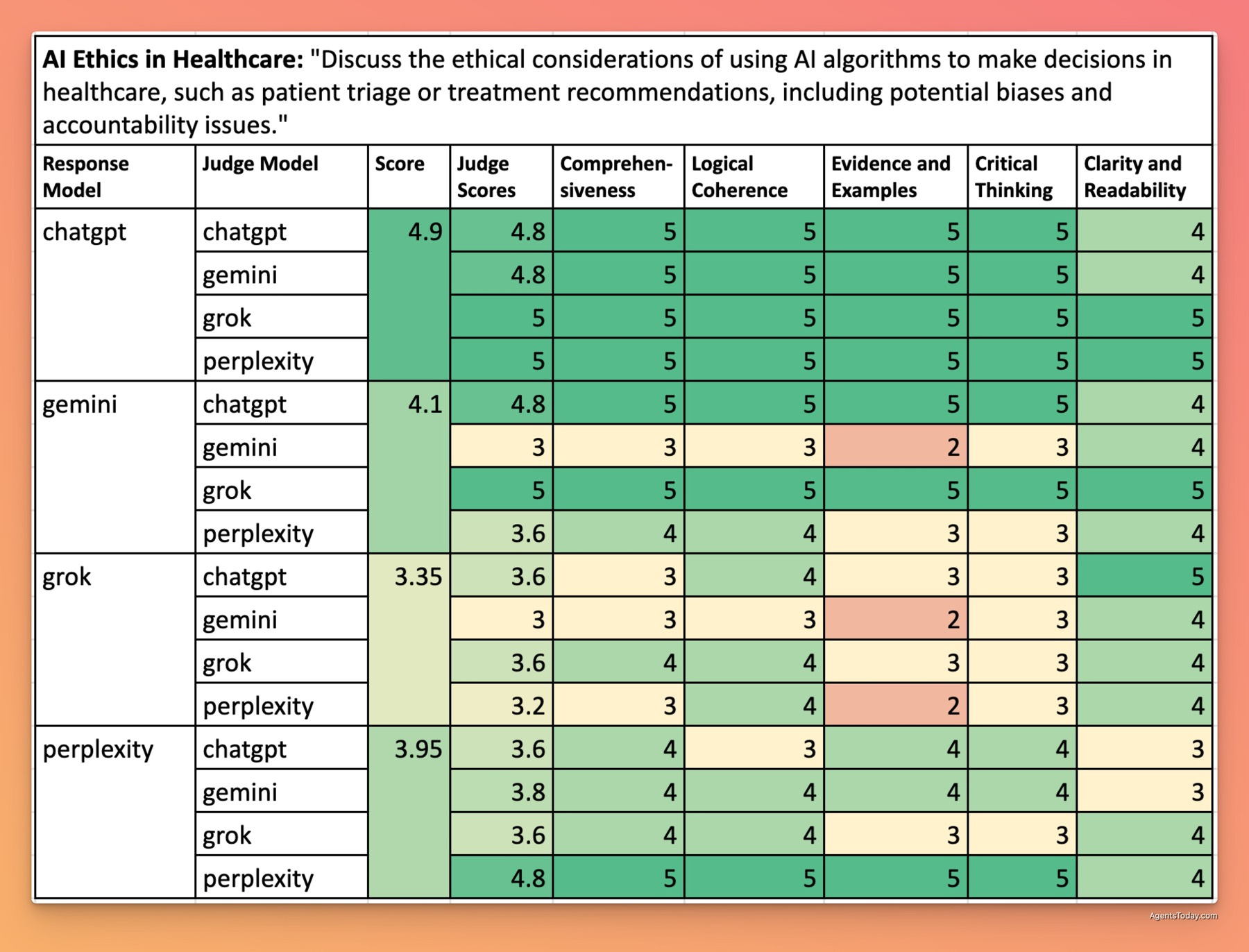
AI Ethics in Healthcare
ChatGPT again dominated with a near-perfect score of 4.90/5. Its response demonstrated exceptional comprehensiveness, addressing algorithmic bias, data privacy, accountability frameworks, patient autonomy, and the tension between efficiency and ethical care. The analysis included specific examples of AI applications in healthcare settings and potential regulatory approaches.
Perplexity (4.30/5) provided strong coverage with particular emphasis on real-world implementation challenges. Gemini (4.15/5) offered a well-structured analysis but with fewer concrete examples. Grok (3.65/5) covered the basic ethical considerations but lacked the depth and nuance of the other responses.
Political Polarization in Democratic Societies
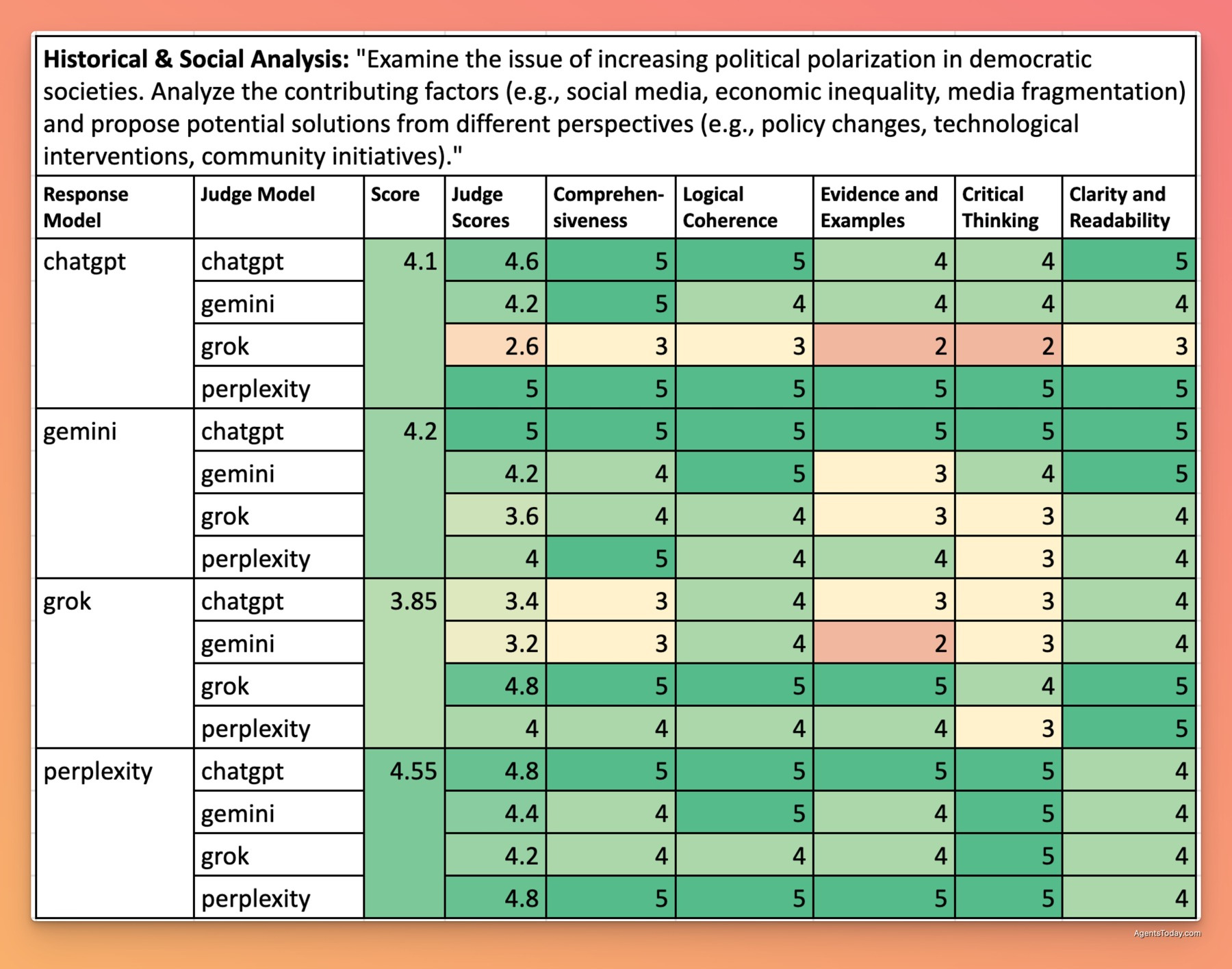
Perplexity took the lead on this topic with a score of 4.55/5, offering exceptional analysis of contributing factors to polarization, including detailed examination of social media echo chambers, economic inequality, and media fragmentation. Its proposed solutions spanned multiple domains and perspectives, from regulatory approaches to grassroots initiatives.
ChatGPT (4.50/5) performed nearly as well, with slightly less emphasis on international comparisons. Gemini (4.10/5) provided a solid analysis with particular strength in examining technological factors. Grok (3.85/5) offered a readable overview but with less substantive evidence and fewer concrete solution proposals.
Quantum Computing and Encryption
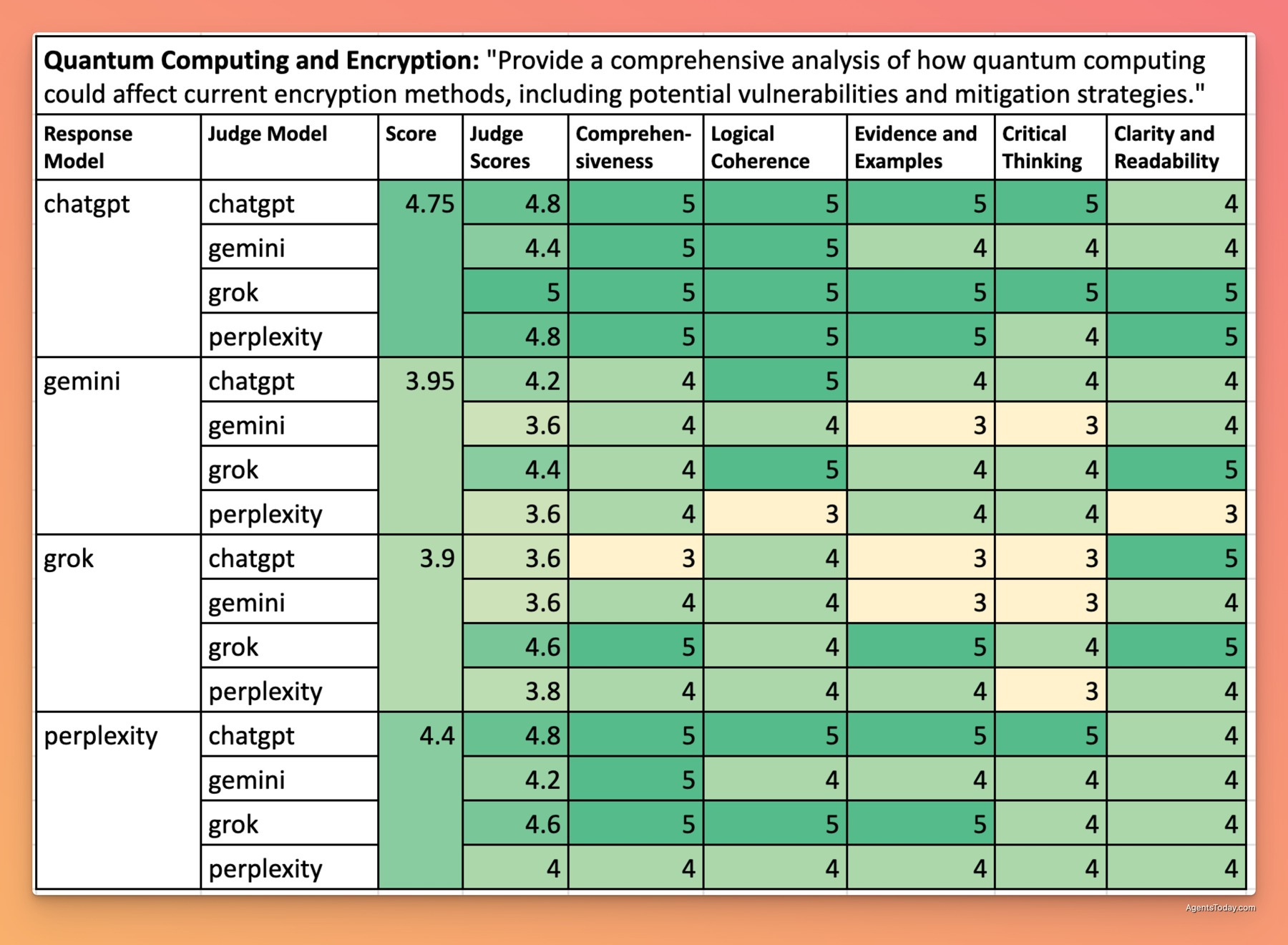
ChatGPT led again with a score of 4.75/5, delivering an exceptional technical analysis of quantum computing threats to current cryptographic systems. Its response included detailed explanations of Shor's algorithm, quantum-resistant encryption methods, and implementation timelines for transitioning to post-quantum cryptography.
Perplexity (4.50/5) provided strong coverage with particular emphasis on current industry and government initiatives. Gemini (4.05/5) offered a well-structured technical explanation but with less depth on implementation challenges. Grok (3.80/5) covered the fundamental concepts clearly but lacked the technical depth and specific examples found in the other responses.
Performance by Evaluation Category

Breaking down performance across specific evaluation criteria reveals each platform's strengths and weaknesses:
Comprehensiveness
ChatGPT (4.75/5)
Perplexity (4.45/5)
Gemini (4.21/5)
Grok (3.81/5)
Insight: ChatGPT consistently provided the most thorough coverage of all aspects of each prompt, rarely missing key dimensions or perspectives. Its responses typically included both breadth and depth, covering not only the main aspects of each topic but also exploring nuanced sub-topics and edge cases.
Logical Coherence
ChatGPT (4.70/5)
Perplexity (4.50/5)
Gemini (4.33/5)
Grok (4.13/5)
Insight: All models performed relatively well in logical coherence, with even the lowest-ranked Grok achieving a respectable 4.13/5. ChatGPT's responses demonstrated particularly strong organizational structure, with clear progression of ideas and well-connected arguments.
Evidence and Examples
ChatGPT (4.50/5)
Perplexity (4.35/5)
Gemini (3.96/5)
Grok (3.44/5)
Insight: This category showed one of the largest performance gaps between the top and bottom performers. ChatGPT and Perplexity consistently supported their claims with specific examples, data points, and references to relevant research or real-world applications. Grok's responses often made claims without sufficient supporting evidence.
Critical Thinking
ChatGPT (4.40/5)
Perplexity (4.30/5)
Gemini (4.00/5)
Grok (3.19/5)
Insight: The critical thinking category revealed the largest performance gap (1.21 points) between the top performer (ChatGPT) and the bottom performer (Grok). ChatGPT consistently demonstrated an ability to analyze issues from multiple perspectives, consider counterarguments, and acknowledge limitations or uncertainties. Grok's responses tended to present more one-dimensional analyses with less consideration of alternative viewpoints.
Clarity and Readability
Grok (4.38/5)
ChatGPT (4.35/5)
Gemini (4.21/5)
Perplexity (3.95/5)
Insight: Surprisingly, Grok—which generally performed worst overall—actually led in Clarity and Readability. This suggests Grok's strength is in producing clear, accessible content even when that content might lack depth or evidence. Perplexity, despite strong performance in other categories, ranked lowest in readability, sometimes producing dense or technical passages that could be challenging for non-experts.
Detailed Performance Analysis by Research Topic
CRISPR Gene Editing Technology - 4.29/5 Overall
ChatGPT - [LINK TO CHATGPT REPORT]
Gemini - [LINK TO GEMINI REPORT]
Perplexity - [LINK TO PERPLEXITY REPORT]
Grok - [LINK TO GROK REPORT]
Quantum Computing and Encryption - 4.25/5 Overall
ChatGPT - [LINK TO CHATGPT QUANTUM COMPUTING REPORT]
Gemini - [LINK TO GEMINI QUANTUM COMPUTING REPORT]
Perplexity Performance - [LINK TO PERPLEXITY QUANTUM COMPUTING REPORT]
Grok Performance - [LINK TO GROK QUANTUM COMPUTING REPORT]
Political Polarization - 4.18/5 Overall
ChatGPT - [LINK TO CHATGPT REPORT]
Gemini - [LINK TO GEMINI REPORT]
Perplexity - [LINK TO PERPLEXITY REPORT]
Grok - [LINK TO GROK REPORT]
AI and Healthcare - 4.08/5 Overall
ChatGPT - [LINK TO CHATGPT REPORT]
Gemini - [LINK TO GEMINI REPORT]
Perplexity - [LINK TO PERPLEXITY REPORT]
Grok - [LINK TO GROK REPORT]